Глава 9.1. Задачи за шампиони – част I
В настоящата глава ще предложим на читателя няколко малко по-трудни задачи, които имат за цел развиване на алгоритмични умения и усвояване на програмни техники за решаване на задачи с по-висока сложност.
По-сложни задачи върху изучавания материал
Ще решим заедно няколко задачи по програмиране, които обхващат изучавания в книгата учебен материал, но по трудност надвишават обичайните задачи от приемните изпити в СофтУни. Ако искате да станете шампиони по основи на програмирането, ви препоръчваме да тренирате решаване на подобни по-сложни задачи, за да ви е лесно на изпитите.
Задача: пресичащи се редици
Имаме две редици:
- редица на Трибоначи (по аналогия с редицата на Фибоначи), където всяко число е сумата от предните три (при дадени начални три числа).
- редица, породена от числова спирала, дефинирана чрез спираловидно обхождане на матрица от числа (дясно, долу, ляво, горе, дясно, долу, ляво, горе и т.н.), стартирайки от нейния център с дадено начално число и стъпка на увеличение, със записване на текущите числа в редицата всеки път, когато направим завой.
Да се напише програма, която намира най-малкото число, което се появява и в двете така дефинирани редици.
Пример
Нека редицата на Трибоначи да започне с 1, 2 и 3. Това означава, че първата редица ще съдържа числата 1, 2, 3, 6, 11, 20, 37, 68, 125, 230, 423, 778, 1431, 2632, 4841, 8904, 16377, 30122, 55403, 101902 и т.н.
Същевременно, нека числата в спиралата да започнат с 5 и спиралата да се увеличава с 2 на всяка стъпка:
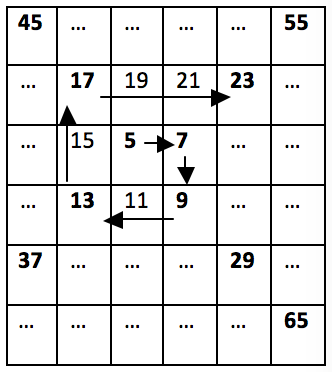
Тогава втората редица ще съдържа числата 5, 7, 9, 13, 17, 23, 29, 37, 45, 55, 65 и т.н. Виждаме, че 37 е първото число (най-малкото), което се среща в редицата на Трибоначи и в спиралата, следователно това е търсеното решение на задачата.
Входни данни
Входните данни трябва да бъдат прочетени от конзолата.
- На първите три реда от входа ще прочетете три цели числа, представляващи първите три числа в редицата на Трибоначи.
- На следващите два реда от входа, ще прочетете две цели числа, представляващи първото число и стъпката за всяка клетка на матрицата за спиралата от числа.
Входните данни винаги ще бъдат валидни и винаги ще са в описания формат. Няма нужда да ги проверявате.
Изходни данни
Резултатът трябва да бъде принтиран на конзолата.
На единствения ред от изхода трябва да принтирате най-малкото число, което се среща и в двете последователности. Ако няма число в диапазона [1 … 1 000 000], което да се среща и в двете последователности, принтирайте "No".
Ограничения
- Всички числа във входа ще бъдат в диапазона [1 … 1 000 000].
- Позволено работно време за програмата: 0.5 секунди.
- Позволена памет: 16 MB.
Примерен вход и изход
| Вход | Изход | Вход | Изход | Вход | Изход |
|---|---|---|---|---|---|
| 1 2 3 5 2 |
37 | 13 25 99 5 2 |
13 | 99 99 99 2 2 |
No |
| Вход | Изход | Вход | Изход |
|---|---|---|---|
| 1 1 1 1 1 |
1 | 1 4 7 23 3 |
23 |
Насоки и подсказки
Задачата изглежда доста сложна и затова ще я разбием на по-прости подзадачи:
- обработване на входа
- генериране на редица на Трибоначи
- генериране на числовата спирала
- намиране на най-малкото общо число за двете редици
Обработване на входа
Първата стъпка от решаването на задачата е да прочетем и обработим входа. Входните данни се състоят от 5 цели числа: 3 за редицата на Трибоначи и 2 за числовата спирала:

След като имаме входните данни, трябва да помислим как ще генерираме числата в двете редици.
Генериране на редица на Трибоначи
За редицата на Трибоначи всеки път ще събираме предишните три стойности и след това ще отместваме стойностите на тези числа (трите предходни) с една позиция напред в редицата, т.е. стойността на първото трябва да приеме стойността на второто, стойността на второто - стойността на третото, а стойността на третото трябва да стане новото намерено число.
Когато сме готови с числото, ще добавяме стойността му във вектор (списък). За да използваме вектори в езика C++, трябва да включим библиотеката vector чрез директивата #include <vector> в началото на кода. Когато имаме създаден вектор, добавянето на елементи в него става с метода push_back(…).
Понеже в условието на задачата е казано, че числата в редиците не превишават 1,000,000, можем да спрем генерирането на тази редица именно при 1,000,000:

Генериране на числова спирала
Трябва да измислим зависимост между числата в числовата спирала, за да можем лесно да генерираме всяко следващо число, без да се налага да разглеждаме матрици и тяхното обхождане. Ако разгледаме внимателно картинката от условието, можем да забележим, че на всеки 2 "завоя" в спиралата числата, които прескачаме, се увеличават с 1, т.е. от 5 до 7 и от 7 до 9 не се прескача нито 1 число, а директно събираме със стъпката на редицата. От 9 до 13 и от 13 до 17 прескачаме едно число, т.е. събираме два пъти стъпката. От 17 до 23 и от 23 до 29 прескачаме две числа, т.е. събираме три пъти стъпката и т.н.
Така виждаме, че при първите две имаме последното число + 1 * стъпката, при следващите две събираме с 2 * стъпката и т.н.
Всеки път, когато искаме да стигнем до следващото число от спиралата, ще трябва да извършваме такива изчисления:

Това, за което трябва да се погрижим, е на всеки две числа нашият множител (нека го наречем "коефициент") да се увеличава с 1 (spiralStepMul++), което може да се постигне с проста проверка за четност (spiralCount % 2 == 0). Целият код от генерирането на спиралата във вектор е даден по-долу:

Намиране на общо число за двете редици
След като сме генерирали числата и в двете редици, можем да пристъпим към обединението им и изграждане на крайното решение. Как ще изглежда то? За всяко от числата в едната редица (започвайки от по-малкото) ще проверяваме дали то съществува в другата. Първото число, което отговаря на този критерий ще бъде отговорът на задачата.
Търсенето във втория вектор ще направим линейно, а за по-любопитните ще оставим да си го оптимизират, използвайки техниката наречена двоично търсене (Binary Search), тъй като вторият вектор се генерира сортиран, т.е. отговаря на изискването за прилагането на този тип търсене.
Ще използваме малко по-специален for цикъл за обработката на всяко число от двата вектора. С дадения по-долу синтаксис всеки един от двата цикъла минава по всяко от числата във векторите едно по едно и ги записва в съответната променлива.
Кодът за намиране на нашето решение ще изглежда така:

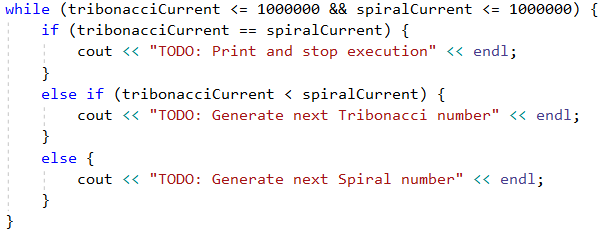
Решението на задачата използва вектори за запазване на стойностите. Векторите не са необходими за решаването на задачата. Съществува алтернативно решение, което генерира числата и работи директно с тях, вместо да ги записва във вектор. Можем на всяка стъпка да проверяваме дали числата от двете редици съвпадат. Ако това е така, ще принтираме на конзолата числото и ще прекратим изпълнението на нашата програма. В противен случай, ще видим текущото число на коя редица е по-малко и ще генерираме следващото, там където "изоставаме". Идеята е, че ще генерираме числа от редицата, която е "по-назад", докато не прескочим текущото число на другата редица и след това обратното, а ако междувременно намерим съвпадение, ще прекратим изпълнението:
Тестване в Judge системата
Тествайте решението си тук: https://judge.softuni.org/Contests/Practice/Index/1372#0.
Задача: магически дати
Дадена е дата във формат "дд-мм-гггг", напр. 15-02-2019. Изчисляваме теглото на тази дата, като вземем всичките ѝ цифри, умножим всяка цифра с останалите след нея и накрая съберем всички получени резултати. В нашия случай имаме 8 цифри: 17032007, така че теглото е 1*7 + 1*0 + 1*3 + 1*2 + 1*0 + 1*0 + 1*7 + 7*0 + 7*3 + 7*2 + 7*0 + 7*0 + 7*7 + 0*3 + 0*2 + 0*0 + 0*0 + 0*7 + 3*2 + 3*0 + 3*0 + 3*7 + 2*0 + 2*0 + 2*7 + 0*0 + 0*7 + 0*7 = 144.
Нашата задача е да напишем програма, която намира всички магически дати - дати между две определени години (включително), отговарящи на дадено във входните данни тегло. Датите трябва да бъдат принтирани в нарастващ ред (по дата) във формат "дд-мм-гггг". Ще използваме само валидните дати в традиционния календар (високосните години имат 29 дни през февруари).
Входни данни
Входните данни трябва да бъдат прочетени от конзолата. Състоят се от 3 реда:
- Първият ред съдържа цяло число: начална година.
- Вторият ред съдържа цяло число: крайна година.
- Третият ред съдържа цяло число: търсеното тегло за датите.
Входните данни винаги ще бъдат валидни и винаги ще са в описания формат. Няма нужда да се проверяват.
Изходни данни
Резултатът трябва да бъде принтиран на конзолата, като последователни дати във формат "дд-мм-гггг", подредени по дата в нарастващ ред. Всяка дата трябва да е на отделен ред. В случай, че няма съществуващи магически дати, да се принтира "No".
Ограничения
- Началната и крайната година са цели числа в периода [1900 - 2100].
- Магическото тегло е цяло число в диапазона [1 … 1000].
- Позволено работно време за програмата: 2 секунди.
- Позволена памет: 16 MB.
Примерен вход и изход
| Вход | Изход | Вход | Изход |
|---|---|---|---|
| 2007 2007 144 |
17-03-2007 13-07-2007 31-07-2007 |
2003 2004 1500 |
No |
| Вход | Изход | Вход | Изход |
|---|---|---|---|
| 2012 2014 80 |
09-01-2013 17-01-2013 23-03-2013 11-07-2013 01-09-2013 10-09-2013 09-10-2013 17-10-2013 07-11-2013 24-11-2013 14-12-2013 23-11-2014 13-12-2014 31-12-2014 |
2011 2012 14 |
01-01-2011 10-01-2011 01-10-2011 10-10-2011 |
Насоки и подсказки
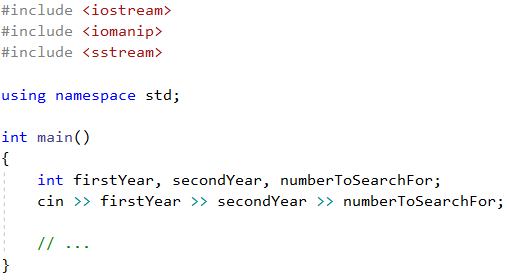
Започваме с вмъкване на необходимите функционалност и с четенето на входните данни от конзолата. В случая имаме вмъкваме библиотеките sstream и iomanip за обръщане на символни низове към дата и обратно и четем 3 цели числа:
Разполагайки с началната и крайната година, е хубаво да разберем как ще минем през всяка дата, без да се объркваме от това колко дена има в месеца и дали годината е високосна и т.н.
Обхождане на всички дати
За обхождането ще се възползваме от функционалността, която ни дава tm типът в C++. Ще си дефинираме променлива за началната дата, което можем да направим, използвайки stringstream и метода get_time(…), чрез които от символен низ можем да създадем обект от тип tm. Знаем, че годината е началната година, която сме получили като параметър, а месецът и денят трябва да са съответно януари и 1-ви:
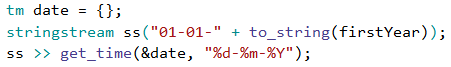
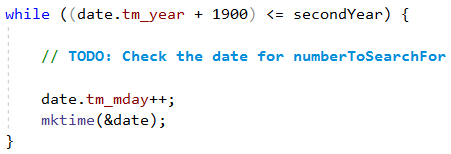
След като имаме началната дата (в променливата date), искаме да направим цикъл, който се изпълнява, докато не превишим крайната година (или докато не преминем 31 декември в крайната година, ако сравняваме целите дати), като на всяка стъпка date се увеличава с по 1 ден.
За да увеличаваме с 1 ден при всяко завъртане, ще използваме tm_mday, което е част от данните на всяка една променлива от тип tm. В C++, за да постигнем това, трябва да увеличим tm_mday с 1, след което да извикаме метода mktime. Добавянето на 1 ден към датата ще помогне C++ да се погрижи вместо нас за прескачането в следващия месец и година, да следи колко дни има даден месец и да се погрижи вместо нас за високосните години:
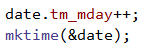
Важна особеност при работата с дати чрез типа tm в C++ е, че променливата tm_year, чрез която можем да вземем годината от дадена дата, има стойност 0 за година 1900 и съответно стойност 119 за година 2019. Това означава, че всеки път когато искаме да вземем реалната година трябва да прибавяме 1900 към tm_year. Друга особеност е, че месец януари се отбелязва със стойност 0 в променливата tm_mon и съответно стойност 11 за декември. Тук ще прибавяме 1 към tm_mon, за да получим номера на месеца в интервал от 1 до 12, каквото е изискването в задачата.
В крайна сметка нашият цикъл ще изглежда по следния начин:
Пресмятане на теглото
Всяка дата се състои от точно 8 символа (цифри) - 2 за деня (d1, d2), 2 за месеца (d3, d4) и 4 за годината (d5 до d8). Това означава, че всеки път ще имаме едно и също пресмятане и може да се възползваме от това, за да дефинираме формулата статично (т.е. да не обикаляме с цикли, реферирайки различни цифри от датата, а да изпишем цялата формула). За да успеем да я изпишем, ще ни трябват всички цифри от датата в отделни променливи, за да направим всички нужни умножения. Използвайки операциите деление и взимане на остатък върху отделните компоненти на датата, чрез tm_mday, tm_mon и tm_year, можем да извлечем всяка цифра:
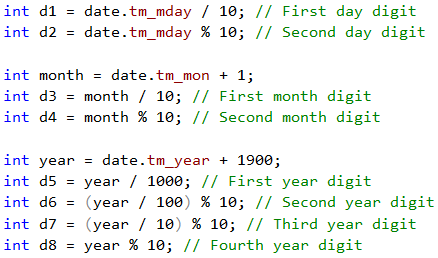
Нека обясним и един от по-интересните редове тук. Нека вземе за пример взимането на втората цифра от годината (d6). При нея делим годината на 100 и взимаме остатък от 10. Какво постигаме така? Първо с деленето на 100 отстраняваме последните 2 цифри от годината (пример: 2018 / 100 = 20). С остатъка от деление на 10 взимаме последната цифра на полученото число (20 % 10 = 0) и така получаваме 0, което е втората цифра на 2018.
Остава да направим изчислението, което ще ни даде магическото тегло на дадена дата. За да не изписваме всички умножения, както е показано в примера, ще приложим просто групиране. Това, което трябва да направим, е да умножим всяка цифра с тези, които са след нея. Вместо да изписваме d1 * d2 + d1 * d3 + … + d1 * d8, може да съкратим този израз до d1 * (d2 + d3 + … + d8), следвайки математическите правила за групиране, когато имаме умножение и събиране. Прилагайки същото опростяване за останалите умножения, получаваме следната формула:
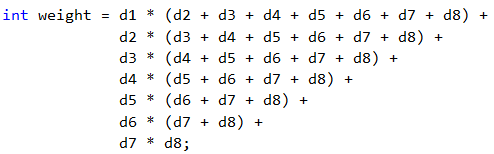
Отпечатване на изхода
След като имаме пресметнато теглото на дадена дата, трябва да проверим дали съвпада с търсеното от нас магическо тегло, за да знаем, дали трябва да се принтира или не. Проверката може да се направи със стандартен if оператор, като трябва да се внимава при принтирането датата да е в правилният формат. За целта ще се възползваме от друг помощен метод в езика C++ - put_time(…), който взима дата от тип tm и символен формат (в нашия случай %d - %m - %Y) и изкарва данните за датата в посочения формат (в нашия случай дата-месец-година):
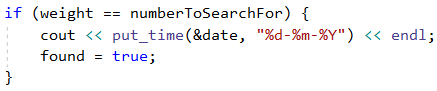
Внимание: тъй като обхождаме датите от началната към крайната, те винаги ще бъдат подредени във възходящ ред, както е по условие.
И накрая, ако не сме намерили нито една дата, отговаряща на условията, ще имаме false стойност във променливата found и ще отпечатаме "No":
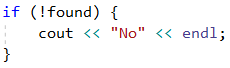
Тестване в Judge системата
Тествайте решението си тук: https://judge.softuni.org/Contests/Practice/Index/1372#1.
Задача: пет специални букви
Дадени са две числа: начало и край. Напишете програма, която генерира всички комбинации от 5 букви, всяка измежду множеството {'a', 'b', 'c', 'd', 'e'}, така че "теглото" на тези 5 букви да е число в интервала [начало … край], включително. Принтирайте ги по азбучен ред, на един ред, разделени с интервал.
Теглото на една буква се изчислява по следния начин:
weight('а') = 5;
weight('b') = -12;
weight('c') = 47;
weight('d') = 7;
weight('e') = -32;
Теглото на редицата от букви c1, c2, …, cn е изчислено, като се премахват всички букви, които се повтарят (от дясно наляво), и след това се пресметне формулата:
weight(c1, c2, …, cn) = 1 * weight(c1) + 2 * weight(c2) + … + n * weight(cn)
Например, теглото на bcddc се изчислява по следния начин:
Първо премахваме повтарящите се букви и получаваме bcd. След това прилагаме формулата: 1 * weight('b') + 2 * weight('c') + 3 * weight('d') = 1 * (-12) + 2 * 47 + 3 * 7 = 103.
Друг пример: weight("cadae") = weight("cade") = 1 * 47 + 2 * 5 + 3 * 7 + 4 * (-32) = -50.
Входни данни
Входните данни се четат от конзолата. Състоят се от два реда:
- Числото за начало е на първия ред.
- Числото за край е на втория ред.
Входните данни винаги ще бъдат валидни и винаги ще са в описания формат. Няма нужда да се проверяват.
Изходни данни
Резултатът трябва да бъде принтиран на конзолата като поредица от низове, подредени по азбучен ред. Всеки низ трябва да бъде отделен от следващия с едно разстояние. Ако теглото на нито един от 5-буквените низове не съществува в зададения интервал, да се принтира "No".
Ограничения
- Числата за начало и край ще бъдат цели числа в диапазона [-10000 … 10000].
- Позволено работно време за програмата: 0.5 секунди.
- Позволена памет: 16 MB.
Примерен вход и изход
| Вход | Изход | Коментар |
|---|---|---|
| 40 42 |
bcead bdcea | weight("bcead") = 41 weight("bdcea") = 40 |
| Вход | Изход |
|---|---|
| -1 1 |
bcdea cebda eaaad eaada eaadd eaade eaaed eadaa eadad eadae eadda eaddd eadde eadea eaded eadee eaead eaeda eaedd eaede eaeed eeaad eeada eeadd eeade eeaed eeead |
| Вход | Изход |
|---|---|
| 200 300 |
baadc babdc badac badbc badca badcb badcc badcd baddc bbadc bbdac bdaac bdabc bdaca bdacb bdacc bdacd bdadc bdbac bddac beadc bedac eabdc ebadc ebdac edbac |
| Вход | Изход |
|---|---|
| 300 400 |
No |
Насоки и подсказки
Като всяка задача, започваме решението с обработване на входните данни:

В задачата имаме няколко основни момента - генерирането на всички комбинации с дължина 5 включващи 5-те дадени букви, премахването на повтарящите се букви и пресмятането на теглото за дадена вече опростена дума. Отговорът ще се състои от всяка дума, чието тегло е в дадения интервал [firstNumber, secondNumber].
Генериране на всички комбинации
За да генерираме всички комбинации с дължина 1 използвайки 5 символа, бихме използвали цикъл от 0..4, като всяко число от цикъла ще искаме да отговаря на един символ. За да генерираме всички комбинации с дължина 2 използвайки 5 символа (т.е. "aa", "ab", "ac", …, "ba", …), бихме направили два вложени цикъла, всеки обхождащ цифрите от 0 до 4, като отново ще направим, така че всяка цифра да отговаря на конкретен символ. Тази стъпка ще повторим 5 пъти, така че накрая да имаме 5 вложени цикъла с индекси i1, i2, i3, i4 и i5:

Имайки всички 5-цифрени комбинации, трябва да намерим начин да "превърнем" петте цифри в дума с буквите от 'a' до 'e'. Един от начините да направим това е, като си предефинираме стринг променлива, съдържаща буквите, които имаме:
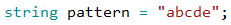
и за всяка цифра взимаме буквата от конкретната позиция. По този начин числото 00000 ще стане "aaaaa", числото 02423 ще стане "acecd". Можем да направим стринга от 5 букви по следния начин:

Друг начин: можем да преобразуваме цифрите до букви, използвайки подредбата им в ASCII таблицата. Изразът (char)((int)'a' + i) ще ни даде резултата 'a' при i = 0, 'b' при i = 1, 'c' при i = 2 и т.н.
Така вече имаме генерирани всички 5-буквени комбинации и можем да продължим със следващата част от задачата.
Внимание: тъй като сме подбрали pattern, съобразен с азбучната подредба на буквите и циклите се въртят по подходящ начин, алгоритъмът ще генерира думите в азбучен ред и няма нужда от допълнително сортиране преди извеждане.
Премахването на повтарящи се букви
След като имаме вече готовия низ, трябва да премахнем всички повтарящи се символи. Ще направим тази операция, като добавяме буквите от ляво надясно в нов низ и всеки път преди да добавим буква ще проверяваме дали вече я има - ако я има ще я пропускаме, а ако я няма ще я добавяме. За начало ще добавим първата буква към началния символен низ (string):

След това ще направим същото и с останалите 4, проверявайки всеки път дали ги има чрез метода find(…). Когато методът find(…) върне отрицателлното число -1, това означава, че символният низ, който търсим не е намерен. За служебната стойност "не е намерено" ползваме string::npos. Тази част от кода можем да имплементираме и с цикъл по символите на fullWord, но това ще оставим на читателя за упражнение. По-долу е показан по-мързеливия начин с copy-paste:

Методът find(…) връща индекса на конкретния елемент, ако бъде намерен или -1, ако елементът не бъде намерен. Следователно всеки път, когато получим -1, ще означава, че все още нямаме тази буква в новия низ с уникални букви и можем да я добавим, а ако получим стойност различна от -1, ще означава, че вече имаме буквата и няма да я добавяме.
Пресмятане на теглото
Пресмятането на теглото е просто обхождане на уникалната дума (word), получена в миналата стъпка, като за всяка буква трябва да вземем теглото ѝ и да я умножим по позицията. За всяка буква в обхождането трябва да пресметнем с каква стойност ще умножим позицията ѝ, например чрез използването на поредица от if конструкции:

След като имаме стойността на дадената буква, следва да я умножим по позицията ѝ. Тъй като индексите в стринга се различават с 1 от реалните позиции, т.е. индекс 0 е позиция 1, индекс 1 е позиция 2 и т.н., ще добавим 1 към индексите. Затова на последния ред от цикъла имаме израза:
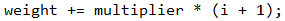
Всички получени междинни резултати трябва да бъдат добавени към обща сума (weight) за всяка една буква от 5-буквената комбинация.
Оформяне на изхода
Дали дадена дума трябва да се принтира, се определя по нейната тежест. Трябва ни условие, което да определи дали текущата тежест е в интервала [начало … край], подаден ни на входа в началото на програмата. Ако това е така, принтираме пълната дума (fullWord).
Внимавайте да не принтирате думата от уникални букви (word), тя ни бе необходима само за пресмятане на тежестта!
Думите са разделени с интервал и ще ги натрупваме в междинна променлива result, която е дефинирана като празен низ в началото:

Финални щрихи
Условието е изпълнено с изключение случаите, в които нямаме нито една дума в подадения интервал. За да разберем дали сме намерили такава дума, можем просто да проверим дали низът result има началната си стойност (а именно празен низ), чрез метода empty() и ако е така - отпечатваме "No", иначе печатаме целия низ без последния интервал. Махането на последния интервал от символния низ result можем да направим чрез метода substr(…), който ще ни върне подниза започващ от 0 и имащ дължина: дължината на символния низ минус 1.

За по-любознателните читатели ще оставим за домашно да оптимизират работата на циклите като измислят начин да намалят броя итерации на вътрешните цикли.
Тестване в Judge системата
Тествайте решението си тук: https://judge.softuni.org/Contests/Practice/Index/1372#2.